3D Robot Simulation & RL Training in PyBullet
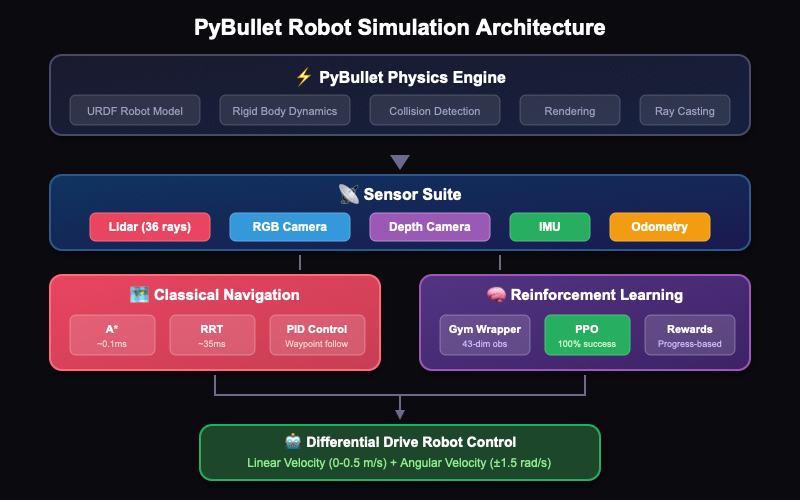
A complete 3D physics simulation environment for differential drive robot navigation and reinforcement learning using PyBullet. Building on the foundations of 2D simulation (IR-SIM), this project takes the next step into realistic 3D environments with full sensor simulation, path planning algorithms, and PPO-based RL training achieving 100% success rate.
The Challenge
2D simulations are great for learning, but real robots live in a 3D world with mass, momentum, friction, and gravity. The challenge was to create a simulation environment that:
- Models realistic 3D physics and robot dynamics
- Simulates multiple sensor modalities (Lidar, Camera, IMU, Odometry)
- Supports both classical navigation and RL-based control
- Runs fast enough for iterative development and RL training
- Provides a platform for experimenting with path planning algorithms
The goal: train an RL agent to navigate a cluttered warehouse environment with 31 obstacles, achieving consistent goal-reaching behavior.
Key Features
Full Sensor Suite
- 360° Lidar with 36 rays (10° resolution, 5m range)
- RGB camera (320×240, 60° FOV)
- Depth camera for distance perception
- IMU with configurable noise (accelerometer + gyroscope)
- Differential drive odometry
Path Planning
- A* grid-based planner (~0.1ms planning time)
- RRT continuous-space planner (~35ms, smoother paths)
- PID-based waypoint following
Reinforcement Learning
- Gymnasium-compatible environment wrapper
- 43-dimensional observation space
- Continuous action space (forward velocity + angular velocity)
- PPO training with Stable Baselines3
Multiple Environments
- Warehouse: 31 obstacles with organized aisles
- Street: Buildings and random urban obstacles
- Maze: Wall-based navigation challenge
Technologies Used
| Category | Technologies |
|---|---|
| Simulation | PyBullet, URDF |
| RL Framework | Stable Baselines3, Gymnasium |
| Path Planning | A*, RRT |
| Control | PID Controller |
| Visualization | PyBullet GUI, Matplotlib |
| Platform | Python 3.10, Conda, Apple Silicon (MPS) |
Architecture
┌─────────────────────────────────────────────────────────────┐
│ PyBullet Physics Engine │
├─────────────────────────────────────────────────────────────┤
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────────┐ │
│ │ URDF Robot │ │ Environment │ │ Sensor System │ │
│ │ Model │ │ Builder │ │ (Lidar/Camera/ │ │
│ │ │ │ │ │ IMU/Odom) │ │
│ └──────────────┘ └──────────────┘ └──────────────────┘ │
├─────────────────────────────────────────────────────────────┤
│ Navigation Layer │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────────┐ │
│ │ A* Planner │ │ RRT Planner │ │ PID Controller │ │
│ └──────────────┘ └──────────────┘ └──────────────────┘ │
├─────────────────────────────────────────────────────────────┤
│ RL Training Layer │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────────┐ │
│ │ Gym Wrapper │ │ PPO Agent │ │ Reward Shaping │ │
│ └──────────────┘ └──────────────┘ └──────────────────┘ │
└─────────────────────────────────────────────────────────────┘
The RL Training Journey
The Problem
Initial RL training was a disaster. The robot would spin in circles, oscillate back and forth, or stop just short of the goal. Success rate: 0-2 out of 5 episodes.
Root Causes Identified
- Complex reward function with too many competing terms
- Missing observation — agent couldn't perceive distance to goal
- Oversensitive stuck detection — 32,000 false triggers per episode
- Harsh penalties crushing exploration
The Fix
Simplified the reward function to focus on what matters:
| Component | Value | Purpose |
|---|---|---|
| Progress | +1.0/meter | Primary signal — move toward goal |
| Goal reached | +50.0 | Clear success signal |
| Collision | -10.0 | Moderate, not crushing |
| Time | -0.01/step | Encourage efficiency |
| Heading alignment | +0.1 | Guide early learning |
Final Results
| Metric | Value |
|---|---|
| Success Rate | 5/5 (100%) |
| Average Reward | 57.43 ± 3.83 |
| Average Steps | 164 ± 58 |
| Distance Traveled | 3.06m ± 1.09m |
What I Learned
Simplicity Wins
Both the navigation controller and reward function improved dramatically when I removed complexity. My initial navigation controller had stuck detection, oscillation prevention, and multiple state machines — and it failed. A simple PID controller succeeded.
Observation Space Design
That missing distance-to-goal observation was a showstopper. The agent literally couldn't perceive when it was close to success. Always verify your observations contain the information needed for the task.
Balance Your Penalties
Harsh penalties (-50 for collision) prevented exploration. Moderate penalties (-10) guide behavior without crushing the learning signal.
Performance Profiling Matters
I discovered visualization was consuming 424ms per frame — not physics or planning. Reducing update frequency brought the simulation from 0.8 FPS to 4.2 FPS.
Path Planning Trade-offs
A* plans faster (~0.1ms) but RRT produced better overall navigation (fewer replanning cycles). Always measure end-to-end, not just component performance.
Running the Project
Quick Start
# Clone repository git clone https://github.com/padawanabhi/pybullet_sim.git cd pybullet_sim # Setup environment (conda recommended for macOS) conda create -n pybullet_sim python=3.10 conda activate pybullet_sim conda install -c conda-forge pybullet pip install -r requirements.txt # Test basic simulation python scripts/01_hello_pybullet.py # Run navigation demo python scripts/06_navigate_environment.py # Train RL agent python scripts/train_ppo.py --timesteps 1000000 # Evaluate trained model python scripts/evaluate.py --episodes 5
Training Configuration
# PPO hyperparameters used { "algorithm": "PPO", "timesteps": 1_000_000, "parallel_envs": 4, "learning_rate": 3e-4, "n_steps": 2048, "batch_size": 64, "device": "mps" # Apple Silicon }
Future Improvements
- Multi-Goal Training: Sequential waypoint navigation
- Dynamic Obstacles: Moving targets and obstacles
- Curriculum Learning: Gradually increase environment complexity
- Sim-to-Real Transfer: Deploy to physical differential drive robot
- Additional Algorithms: Compare SAC, TD3 performance
- Domain Randomization: Vary physics parameters for robustness
Resources
- GitHub Repository: padawanabhi/pybullet_sim
- PyBullet Documentation: docs.google.com/document/d/10sXEhzFRSnvFcl3XxNGhnD4N2SedqwdAvK3dsihxVUA
- Stable Baselines3: stable-baselines3.readthedocs.io
- Gymnasium: gymnasium.farama.org