3D-Robotersimulation & RL-Training in PyBullet
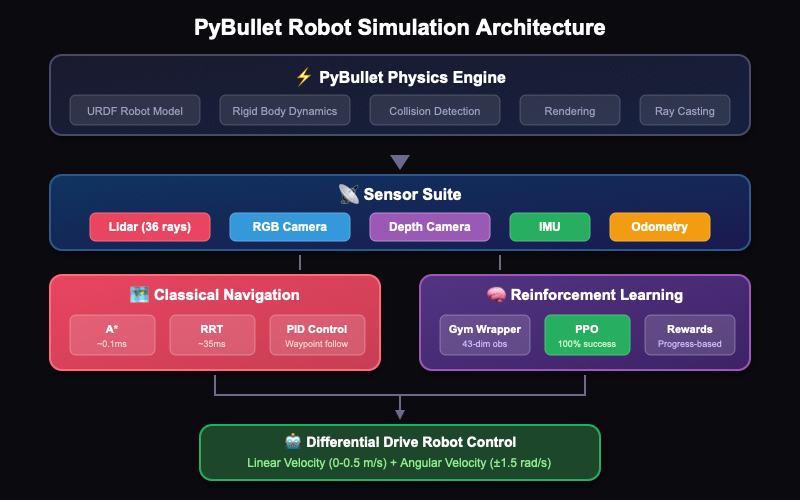
Eine vollständige 3D-Physiksimulationsumgebung für Differential-Antrieb-Roboternavigation und Reinforcement Learning mit PyBullet. Aufbauend auf den Grundlagen der 2D-Simulation (IR-SIM) macht dieses Projekt den nächsten Schritt in realistische 3D-Umgebungen mit vollständiger Sensorsimulation, Pfadplanungsalgorithmen und PPO-basiertem RL-Training, das eine 100%ige Erfolgsrate erreicht.
Die Herausforderung
2D-Simulationen sind großartig zum Lernen, aber echte Roboter leben in einer 3D-Welt mit Masse, Impuls, Reibung und Schwerkraft. Die Herausforderung war, eine Simulationsumgebung zu erstellen, die:
- Realistische 3D-Physik und Roboterdynamik modelliert
- Mehrere Sensormodalitäten simuliert (Lidar, Kamera, IMU, Odometrie)
- Sowohl klassische Navigation als auch RL-basierte Steuerung unterstützt
- Schnell genug für iterative Entwicklung und RL-Training läuft
- Eine Plattform für Experimente mit Pfadplanungsalgorithmen bietet
Das Ziel: Trainiere einen RL-Agenten zur Navigation in einer unübersichtlichen Lagerhausumgebung mit 31 Hindernissen, Erreichen konsistenten Zielerreichungs-Verhaltens.
Hauptfunktionen
Vollständiges Sensor-Set
- 360° Lidar mit 36 Strahlen (10° Auflösung, 5m Reichweite)
- RGB-Kamera (320×240, 60° Sichtfeld)
- Tiefenkamera für Entfernungswahrnehmung
- IMU mit konfigurierbarem Rauschen (Beschleunigungsmesser + Gyroskop)
- Differential-Antrieb-Odometrie
Pfadplanung
- A*-Grid-basierter Planer (~0.1ms Planungszeit)
- RRT-Kontinuum-Raum-Planer (~35ms, glattere Pfade)
- PID-basierte Wegpunkt-Verfolgung
Reinforcement Learning
- Gymnasium-kompatibler Umgebungs-Wrapper
- 43-dimensionaler Beobachtungsraum
- Kontinuierlicher Aktionsraum (Vorwärtsgeschwindigkeit + Winkelgeschwindigkeit)
- PPO-Training mit Stable Baselines3
Mehrere Umgebungen
- Lagerhaus: 31 Hindernisse mit organisierten Gängen
- Straße: Gebäude und zufällige urbane Hindernisse
- Labyrinth: Wandbasierte Navigationsherausforderung
Verwendete Technologien
| Kategorie | Technologien |
|---|---|
| Simulation | PyBullet, URDF |
| RL-Framework | Stable Baselines3, Gymnasium |
| Pfadplanung | A*, RRT |
| Steuerung | PID-Controller |
| Visualisierung | PyBullet GUI, Matplotlib |
| Plattform | Python 3.10, Conda, Apple Silicon (MPS) |
Architektur
┌─────────────────────────────────────────────────────────────┐
│ PyBullet Physics Engine │
├─────────────────────────────────────────────────────────────┤
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────────┐ │
│ │ URDF Robot │ │ Environment │ │ Sensor System │ │
│ │ Model │ │ Builder │ │ (Lidar/Camera/ │ │
│ │ │ │ │ │ IMU/Odom) │ │
│ └──────────────┘ └──────────────┘ └──────────────────┘ │
├─────────────────────────────────────────────────────────────┤
│ Navigation Layer │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────────┐ │
│ │ A* Planner │ │ RRT Planner │ │ PID Controller │ │
│ └──────────────┘ └──────────────┘ └──────────────────┘ │
├─────────────────────────────────────────────────────────────┤
│ RL Training Layer │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────────┐ │
│ │ Gym Wrapper │ │ PPO Agent │ │ Reward Shaping │ │
│ └──────────────┘ └──────────────┘ └──────────────────┘ │
└─────────────────────────────────────────────────────────────┘
Die RL-Trainingsreise
Das Problem
Das anfängliche RL-Training war ein Desaster. Der Roboter drehte sich im Kreis, oszillierte hin und her oder stoppte kurz vor dem Ziel. Erfolgsrate: 0-2 von 5 Episoden.
Identifizierte Root Causes
- Komplexe Reward-Funktion mit zu vielen konkurrierenden Termen
- Fehlende Beobachtung — Agent konnte Entfernung zum Ziel nicht wahrnehmen
- Überempfindliche Stuck-Erkennung — 32.000 falsche Trigger pro Episode
- Harte Strafen zerstörten Exploration
Die Lösung
Vereinfachte die Reward-Funktion, um sich auf das Wesentliche zu konzentrieren:
| Komponente | Wert | Zweck |
|---|---|---|
| Fortschritt | +1.0/Meter | Primäres Signal — bewege dich zum Ziel |
| Ziel erreicht | +50.0 | Klares Erfolgssignal |
| Kollision | -10.0 | Mäßig, nicht zerstörend |
| Zeit | -0.01/Schritt | Ermutige Effizienz |
| Kursausrichtung | +0.1 | Leite frühes Lernen |
Endergebnisse
| Metrik | Wert |
|---|---|
| Erfolgsrate | 5/5 (100%) |
| Durchschnittliche Belohnung | 57.43 ± 3.83 |
| Durchschnittliche Schritte | 164 ± 58 |
| Zurückgelegte Distanz | 3.06m ± 1.09m |
Was ich gelernt habe
Einfachheit gewinnt
Sowohl der Navigationscontroller als auch die Reward-Funktion verbesserten sich dramatisch, als ich Komplexität entfernte. Mein anfänglicher Navigationscontroller hatte Stuck-Erkennung, Oszillations-Prävention und mehrere Zustandsmaschinen—und er scheiterte. Ein einfacher PID-Controller war erfolgreich.
Beobachtungsraum-Design
Diese fehlende Entfernung-zum-Ziel-Beobachtung war ein Showstopper. Der Agent konnte buchstäblich nicht wahrnehmen, wenn er dem Erfolg nahe war. Immer verifizieren, dass deine Beobachtungen die für die Aufgabe benötigten Informationen enthalten.
Balance deine Strafen
Harte Strafen (-50 für Kollision) verhinderten Exploration. Mäßige Strafen (-10) leiten Verhalten, ohne das Lernsignal zu zerstören.
Performance-Profiling ist Wichtig
Ich entdeckte, dass Visualisierung 424ms pro Frame verbrauchte—nicht Physik oder Planung. Reduzierung der Update-Frequenz brachte die Simulation von 0.8 FPS auf 4.2 FPS.
Pfadplanungs-Trade-offs
A* plant schneller (~0.1ms), aber RRT produzierte bessere Gesamtnavigation (weniger Replanungszyklen). Immer End-to-End messen, nicht nur Komponenten-Performance.
Projekt ausführen
Schnellstart
# Repository klonen git clone https://github.com/padawanabhi/pybullet_sim.git cd pybullet_sim # Umgebung einrichten (conda empfohlen für macOS) conda create -n pybullet_sim python=3.10 conda activate pybullet_sim conda install -c conda-forge pybullet pip install -r requirements.txt # Basis-Simulation testen python scripts/01_hello_pybullet.py # Navigations-Demo ausführen python scripts/06_navigate_environment.py # RL-Agent trainieren python scripts/train_ppo.py --timesteps 1000000 # Trainiertes Modell evaluieren python scripts/evaluate.py --episodes 5
Trainings-Konfiguration
# Verwendete PPO-Hyperparameter { "algorithm": "PPO", "timesteps": 1_000_000, "parallel_envs": 4, "learning_rate": 3e-4, "n_steps": 2048, "batch_size": 64, "device": "mps" # Apple Silicon }
Zukünftige Verbesserungen
- Multi-Ziel-Training: Sequenzielle Wegpunkt-Navigation
- Dynamische Hindernisse: Bewegliche Ziele und Hindernisse
- Curriculum Learning: Allmähliche Erhöhung der Umgebungskomplexität
- Sim-to-Real-Transfer: Deployment auf physischen Differential-Antrieb-Roboter
- Zusätzliche Algorithmen: Vergleich von SAC-, TD3-Performance
- Domain Randomization: Variation von Physikparametern für Robustheit
Ressourcen
- GitHub-Repository: padawanabhi/pybullet_sim
- PyBullet-Dokumentation: docs.google.com/document/d/10sXEhzFRSnvFcl3XxNGhnD4N2SedqwdAvK3dsihxVUA
- Stable Baselines3: stable-baselines3.readthedocs.io
- Gymnasium: gymnasium.farama.org